tensorflow에서 slim을 이용한 채널 이미지 분류 머신러닝 학습 방법을 알아보겠습니다. 여기서는 기존의 예가 아닌 내가 만든 사용자 이미지를 slim에 넣어서 학습해 보겠습니다.
tensorflow에서 slim을 이용한 채널 이미지 분류 머신러닝
해당 작업은 다음과 같은 순서로 진행됩니다.
- 이미지를 보고 방송사 정보 분류 소개
- 분류를 위한 머신런닝용 이미지 제작
- 환경 설정
- 이미지를 tfrecord 데이터로 변환
- 학습
- 평가
만약, 아직 slim 예제를 실행해 보지 못한 분은 이전 예제를 한번 보고 오시는걸 권해 드립니다.
이미지를 보고 방송사 정보 분류 소개
이미지 분류 작업에 있어서, 어떤 이미지를 얼마나 학습을 시키면 만족할만한 결과를 얻을 수 있을까요?
Flowers 예제가 있지만, 이번에는 직접 이미지를 만들어서 분류를 해볼까 하고, 그 이미지 분류의 예로 채널 분류하는 걸 만들고자 합니다.
방송 화면에는 보통 각 채널마다 고유의 워터마크가 들어있기 때문에 이것을 이용하는 겁니다.
그래서, 방송화면을 캡쳐하고, 캡쳐 이미지를 방송사별로 분류하여 학습 시키고자 했는데, 마침 slim이 매우 적합한 모델인거죠.
(처음에는 동영상에서 이미지를 자동 캡쳐할까도 고민 했는데, 특정 프로만 나올듯 해서 방송 직접 캡쳐했습니다.)
분류를 위한 머신런닝용 이미지 제작
일단 채널별로 학습에 필요한 이미지가 필요합니다. 저는 약 20여개 채널 이미지를 캡쳐해서 모았습니다.
방송사 화면 캡쳐를 위해서 OMVS 라는걸 이용했습니다. 사용 방법은 이게 핵심이 아니라서 넘어가겠습니다.
어차피 제가 예를 들어서 진행하는 부분이기 때문에 이 부분은 본인이 만든 이미지에 맞게 맞추면 됩니다.
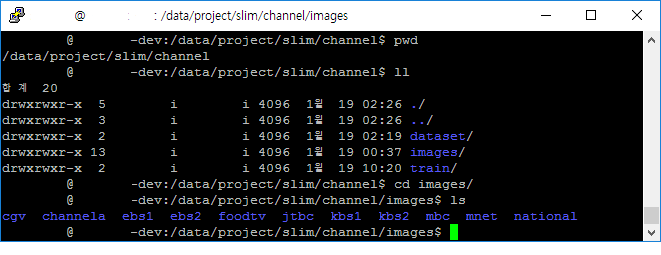
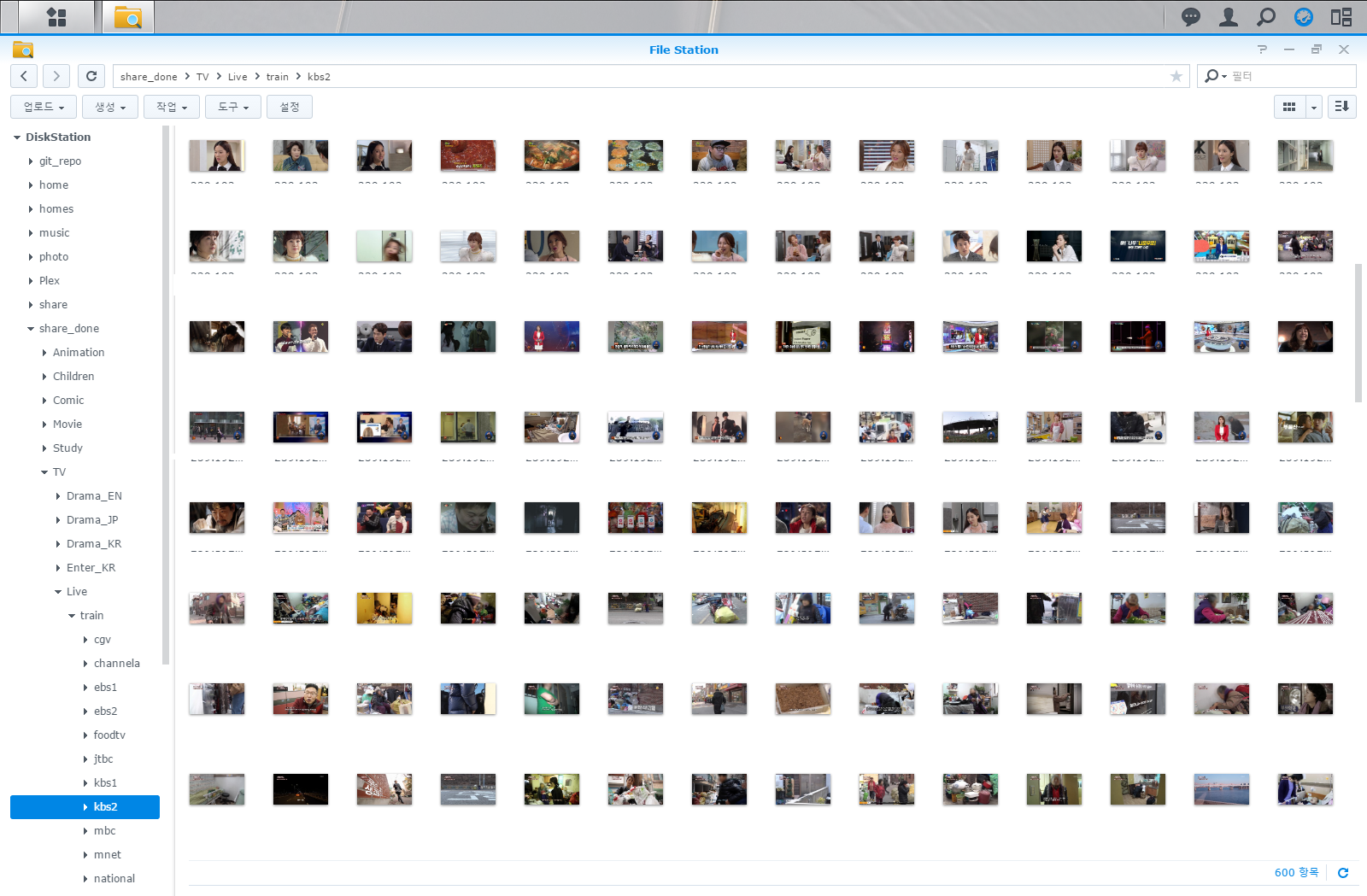
중요한건 폴더(Class)별로 이미지를 모아두는 겁니다. 아래 이미지를 참고하시면 됩니다.
이미지 약 5천여장에 대해서 채널 정보가 빠진 이미지는 한땀 한땀 직접 삭제처리 했습니다.
(이게 제일 힘들지만 중요한 것 같습니다. 쓰레기 학습 데이터가 들어가는건 최대한 배제했습니다.
노이즈라 취급하기에 학습 이미지가 많지 않기 때문에 최대한 패턴이 보이는 이미지를 사용합니다.)
이미지는 이렇게 모아져 있고, 여기서 학습에 사용할 이미지로 채널 정보(워터마크)가 보이지 않는 이미지는 삭제했습니다.
환경 설정
slim model 다운로드
해당 예제는 tensorflow 0.12 환경에서 python 2.7로 실행합니다. (GTX 1060 6GB 환경에서 학습 – inception_v3 모델 사용)
저는 slim models을 /data/project/models 폴더에 받아서 작업을 진행했습니다.
따라서, slim을 실제로 구동하는 소스 폴더는 /data/project/models/slim 입니다.
cd /data/project git clone https://github.com/tensorflow/models.git cd models/slim
학습용 이미지 폴더 구성
slim 학습을 위해서 다음과 같이 폴더를 구성하고 진행할 예정입니다. 이 부부은 본인 취향에 맞게 세팅하시면 됩니다.
참고로 저는 SSD랑 HDD가 있는데, 학습 데이터는 HDD에서 사용하기 위해서 임의로 마운트를 /data 폴더에 맞춘 상태입니다.
/data/project/slim 디렉토리는 제가 slim으로 학습하기 위해서 만든 임의의 폴더이니 본인 상황에 맞게 사용하시면 됩니다.
- slim 학습에 사용할 프로젝트 폴더 생성 : /data/project/slim/channel
- 학습에 사용할 이미지 모음 폴더 생성 후 이미지 데이터 복사 : /data/project/slim/channel/images
- 학습에 필요한 이미지 변환 데이터셋 폴더 생성 : /data/project/slim/channel/dataset
- 학습 결과가 저장될 폴더 생성 : /data/project/slim/channel/train
학습용 환경 변수 선언
학습할 때, 매번 폴더를 반복해서 사용하면 다소 불편합니다.
그래서 폴더를 생성하고 나서 미리 환경변수를 등록합니다.
굳이 이렇게 하지 않고, slim 예제에 있는 것처럼 전체 경로를 사용하셔도 동일합니다.
export SLIM_CHANNEL_DIR=/data/project/slim/channel
export IMAGE_DIR=${SLIM_CHANNEL_DIR}/images
export DATASET_DIR=${SLIM_CHANNEL_DIR}/dataset
export TRAIN_DIR=${SLIM_CHANNEL_DIR}/train
이미지를 tfrecord 데이터로 변환
tensorflow에서 slim을 이용한 채널 이미지 분류 머신러닝 하기 위해서는 이미지를 tfrecord로 변환 합니다.
기존 flowers 예제는 jpg 이미지를 이용하지만 저는 png를 이용할 것이기 때문에 해당 부분을 수정합니다.
(저는 python을 잘 모르기 때문에, 혹시 잘못된 부분 있으면 알려주시면 감사드립니다.)
특히 slim 모델 예제중 flowers는 이미지를 폴더별로 분류해서 학습합니다.
따라서, flowers 라는 예제와 동일한 환경으로 channel 이라는 이름으로 학습합니다.
원래라면, flowers 예제 흐름상 이미지를 원격지에서 이미지 압축파일을 다운로드 받아서 압축을 풀고, 다운로드 받은 이미지를 tfrecord로 변환하고 해당 원본 이미지는 지우는 프로세스로 진행됩니다.
하지만, 제가 사용할 이미지는 폴더별로 이미 구분하여 모아 놓았기 때문에 다운로드하여 압축을 푼 상태에서 바로 진행하도록 합니다.
그래서 다운로드 하는 부분은 제거하고, flowers 이름은 channel로 변경해서 진행하겠습니다.
소스코드 변경
다음의 파일을 수정합니다. : /data/project/models/slim/download_and_convert_data.py
from datasets import download_and_convert_mnist
# 아래에 추가
from datasets import download_and_convert_channel
elif FLAGS.dataset_name == 'mnist':
download_and_convert_mnist.run(FLAGS.dataset_dir)
# 아래에 추가
elif FLAGS.dataset_name == 'channel':
download_and_convert_channel.run(FLAGS.dataset_dir)
다음의 파일을 수정합니다. : /data/project/models/slim/datasets/data_factory.py
from datasets import mnist
# 추가
from datasets import channel
datasets_map = {
'cifar10': cifar10,
'flowers': flowers,
'imagenet': imagenet,
'mnist': mnist,
# 추가
'channel': channel,
}
다음의 파일을 복사하여 수정합니다. : /data/project/models/slim/datasets/download_and_convert_channel.py (download_and_convert_flowers.py 파일 복사)
# flowers 이미지 다운로드 해제 (직접 미리 폴더에 이미지를 넣어서 사용할 예정)
#_DATA_URL = 'http://download.tensorflow.org/example_images/flower_photos.tgz'
# 평가 개수 수정
_NUM_VALIDATION = 450
# JPG에서 PNG 파일 포맷에 맞추어 수정
class ImageReader(object):
"""Helper class that provides TensorFlow image coding utilities."""
def __init__(self):
# Initializes function that decodes RGB PNG data.
self._decode_png_data = tf.placeholder(dtype=tf.string)
self._decode_png = tf.image.decode_png(self._decode_png_data, channels=3)
def read_image_dims(self, sess, image_data):
image = self.decode_png(sess, image_data)
return image.shape[0], image.shape[1]
def decode_png(self, sess, image_data):
image = sess.run(self._decode_png,
feed_dict={self._decode_png_data: image_data})
assert len(image.shape) == 3
assert image.shape[2] == 3
return image
# flowers_root를 channel_root로 변경
#flower_root = os.path.join(dataset_dir, 'flower_photos')
# 이미지가 들어있는 폴더는 dataset 지정 폴더의 images 서브 폴더가 됩니다.
channel_root = os.path.join(dataset_dir, 'images')
directories = []
class_names = []
for filename in os.listdir(channel_root):
path = os.path.join(channel_root, filename)
# tfrecord 파일의 네이밍 수정
def _get_dataset_filename(dataset_dir, split_name, shard_id):
output_filename = 'channel_%s_%05d-of-%05d.tfrecord' % (
# tf예제 이미지 포맷형식 변경
example = dataset_utils.image_to_tfexample(
image_data, 'png', height, width, class_id)
tfrecord_writer.write(example.SerializeToString())
# 이미지 폴더 파일 디렉토리 수정 (어차피 주석 처리되지만 일단 수정)
tmp_dir = os.path.join(dataset_dir, 'images')
# 다운로드 받은 파일 압축 해제하는 소스 주석 처리
#dataset_utils.download_and_uncompress_tarball(_DATA_URL, dataset_dir)
# 작업용 이미지 파일을 삭제하지 않도록 주석처리
#_clean_up_temporary_files(dataset_dir)
다음의 파일을 복사하여 수정합니다. : /data/project/models/slim/datasets/channel.py (flowers.py 파일 복사)
_FILE_PATTERN = 'channel_%s_*.tfrecord'
SPLITS_TO_SIZES = {'train':4500 , 'validation': 450}
_NUM_CLASSES = 11
image to tfRecord 변환 명령
이미지 폴더의 경우, 이미 소스코드에 명시하였기 때문에 별도로 옵션 안 주셔도 됩니다.
python download_and_convert_data.py --dataset_name=channel --dataset_dir=${DATASET_DIR}
학습
학습 명령
python train_image_classifier.py --train_dir=${TRAIN_DIR} --dataset_name=channel \
--dataset_split_name=train --dataset_dir=${DATASET_DIR} \
--model_name=inception_v3 --max_number_of_steps=100000
학습 진행 상태
[layerslider_vc id=”2″]
평가
평가 명령
python eval_image_classifier.py --alsologtostderr --checkpoint_path=${TRAIN_DIR} \
--dataset_dir=${DATASET_DIR} --dataset_name=channel --dataset_split_name=validation \
--model_name=inception_v3
10만번에 학습 대한 평가는 다음과 같습니다. 약 3일 정도(1060) 걸린 것 같습니다.
INFO:tensorflow:Executing eval ops INFO:tensorflow:Executing eval_op 1/5 INFO:tensorflow:Executing eval_op 2/5 INFO:tensorflow:Executing eval_op 3/5 INFO:tensorflow:Executing eval_op 4/5 INFO:tensorflow:Executing eval_op 5/5 INFO:tensorflow:Executing summary op I tensorflow/core/kernels/logging_ops.cc:79] eval/Accuracy[0.714] I tensorflow/core/kernels/logging_ops.cc:79] eval/Recall@5[0.922] INFO:tensorflow:Finished evaluation at 2017-01-23-01:10:54
10만번 기준 정확도가 71%이고, 분류한 것중에서 랭킹 5개 안에 호출될 확률은 92%입니다.
원래라면 첫번째에 나와야지 맞는건데, 5개 안에 나오면 맞다고 보겠다라고 설정하면 그렇다는 의미입니다.
5만번 당시의 Loss와 10만번 당시의 Loss가 비슷한거 봐서는, 더 돌려보면 나아지긴 하겠지만(100만번), 비효율적인듯 싶습니다.
다음 시간에는 해당 이미지 크롭해서 패턴 있는 부분만 새롭게 이미지 만드는 전처리기 붙여서 재학습하고, 비교해 보겠습니다.
요약
최초에는 머신러닝을 배우면서 뭔가 내가 한 번 이미지 만들어서 해 보는 것도 중요하다는 생각이 들었습니다.
그래서 이미지에서 채널 정보를 판단해 내는 모델을 만들어 볼까 했었습니다.
하지만, 구글 Tensorflow의 model인 slim을 이용하면 쉽고 간단하게 이미지 분류가 가능합니다.
tensorflow에서 slim을 이용한 채널 이미지 분류 머신러닝 을 통해서 이미지 분류를 할 수 있었지만, 이와 유사한 작업을 진행하면서 의문이 하나 추가되었습니다.
사람도 반복 학습을 통해서 모르던 사실을 알아 가는데, 좀 더 명확한 데이터를 제시하면, 더 빨리 학습이 되고, 더 좋은 성능을 보여줄까라는 의문입니다.
간단하게 요약하면, 가장 핵심이 되는 패턴인 모서리 부분만 전처리 해서 학습과 평가를 하면 어떨까?라는 겁니다.
이 의문을 풀기 위해서 이미지 전처리 과정을 추가해 보고 그 성능을 비교해 보고자 합니다.
성능과 시간을 모두 잡아내고 더 적은 데이터로도 결과를 이끌어 낼 수 있는지 알고 싶습니다.
다음 시간에는 slim 모델에 특정 이미지의 패턴을 잘 구분할 수 있는 영역이 있는지 전처리를 통해서 어떤 결과 변화가 있는지 알아보겠습니다.
저는 모델을 잘 만들어 낼 자신은 아직은 없습니다.
대신, 데이터를 어떻게 만들어야지 더 효율적인지에 대해서 예제를 통해서 접근해보고 기록하려 합니다.
일단 채널 이미지(FullHD) 분류하는 작업은 71% 정도 결과가 나오는데, 만족할만한 수치는 아니고요.
다음 시간에는 전처리된 이미지(각 모서리별로 이미지 크롭해서 만들어진 이미지로 학습 및 평가)를 가지고 학습하는걸 알아보겠습니다.

