tensorflow im2txt를 이용한 이미지 캡셔닝 이해 및 실습 이라는 주제를 다뤄보고자 합니다. 머신러닝을 이용하면 이미지에 대한 설명을 만들어 내는 것이 가능합니다. 잘 모르시는 분들도 조금은 쉽게 접근 가능할 수 있도록 풀어서 보여드리고자 합니다.

각각의 이미지 위에 문장이 보입니다. 이 문장은 이미지를 넣어주면 알아서 문장을 만들어 주는겁니다. 이게 바로 im2txt를 이용해서 만든 결과물입니다.
tensorflow im2txt를 이용한 이미지 캡셔닝 이해 및 실습
이 내용이 제 기준에서는 쉽지 않았기 때문에 쓸까 말까 고민을 했습니다. 사실 이런거 쓰려면 내용을 이해 못하고 쓰기는 어렵거든요. 이미 im2txt 관련 github에 설명이 잘 올라와 있지만, 전체 맥락을 모두 이해하지 못한 상태에서 보면 처음에는 난해하게 느껴질 수 있습니다. 그래서 되도록이면, tensorflow의 im2txt를 학습하는 과정에서의 느낀 점과 실습 과정을 풀어서 소개해 드릴까 합니다.
순서는 다음과 같습니다.
먼저 이미지 캡셔닝이 무엇인지 이쪽 분야에 어떤 일들이 있었는지 알아볼 겁니다. 그리고 im2txt가 간략하게 어떠한 의미를 갖는지 알아봅니다. 그리고 im2txt에 사용하는 inception_v3 모델에 대해서 간략하게 알아볼 겁니다. 그리고 학습에 사용하는 데이터인 MSCOCO에 대해서 알아봅니다. 지도 학습 머신러닝에서 무엇보다 중요한 학습 데이터가 어떻게 생겼는지 뜯어서 확인해 봐야겠죠. 물론 이를 바탕으로 나만의 데이터도 만들 수 있겠죠. 더 나아가서 모델에서 어떻게 학습하는지 알면 더 좋지만, 아직 여기까지는 어렵지만, 이 부분도 언젠가 다뤄야 할 대목입니다. 마지막으로 이 데이터를 학습하는 방법과 평가하는 방법으로 마무리를 하고자 합니다. 추후 MSCOCO가 아닌 나의 데이터를 가지고 만드는 것도 해볼까 하는데, 이 쪽은 적절한 데이터를 만들어 낼 수 있을런지 의문입니다. 이와 관련된 일을 진행중인데, 이미지는 다양한 방법으로 추려 내고 있는데, 관련 캡셔닝을 만들어 내는게 쉽지 않습니다.
- 개요
- 이미지 캡셔닝 대회
- tensorflow im2txt
- 학습 환경
- tensorflow 버전
- GPU 사용
- inception_v3 모델
- 학습 데이터
- MSCOCO
- im2txt 실습
- 데이터 준비
- 학습
- 평가
- 요약
개요
이미지 캡셔닝 대회
구글에서는 Show and Tell 이라는 이름으로 im2txt를 내놓았습니다. 특히 전년도 우승자인 MS와 비교를 한 자료를 제시합니다.
사람 다음으로 가장 좋은 결과를 내었고 실제 결과물도 매우 우수한 편입니다.
참고 링크 : Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge
tensorflow im2txt
im2txt는 Inception_v3와 다층의 LSTM의 조합으로 이루어진 이미지 to 캡셔닝 모델입니다.
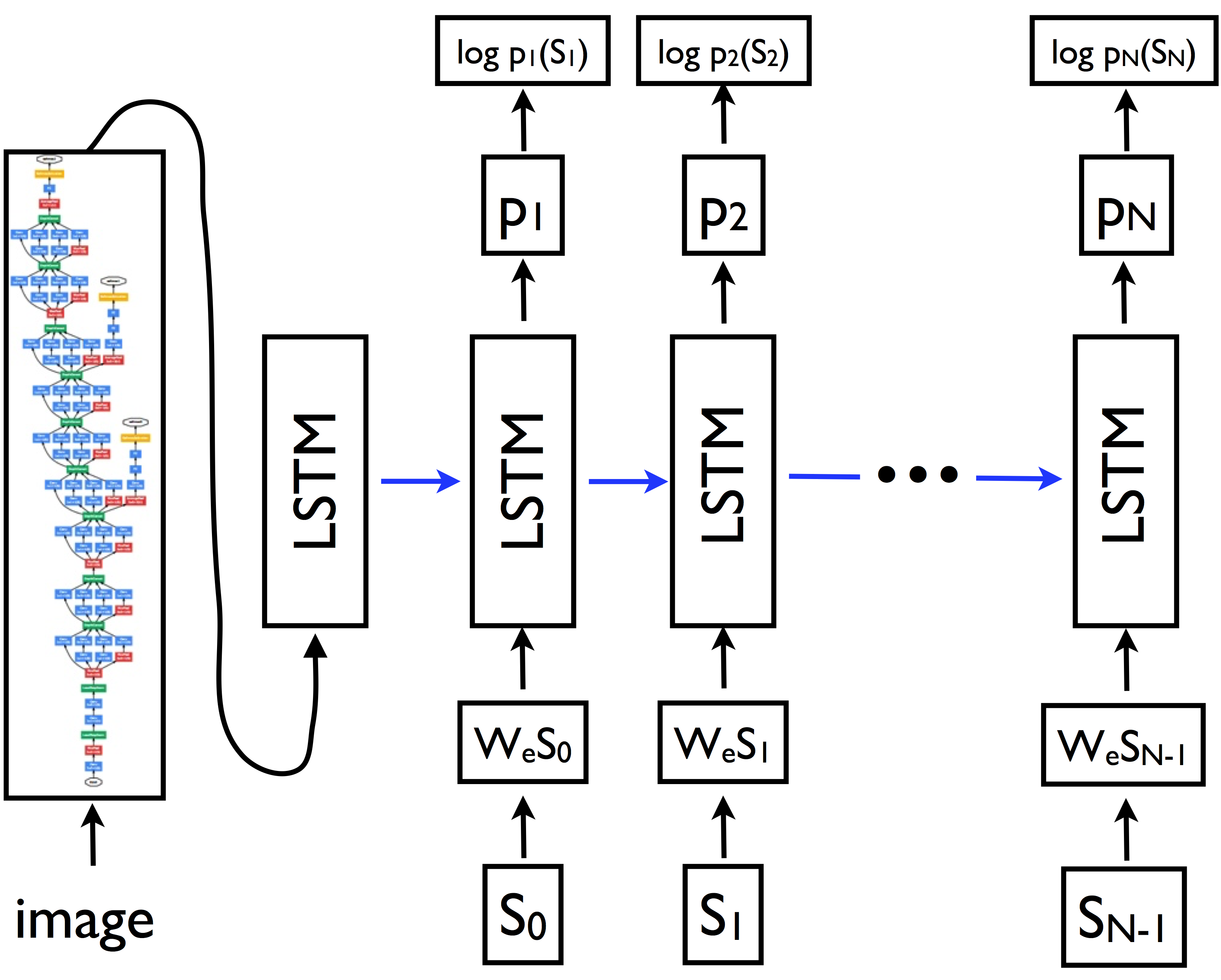
이미지에 대한 형태소를 가지는 키워드를 이용하면 이를 학습데이터로 사용하는 겁니다. 자세한건 inception_v3와 LSTM을 잘 공부해 보고 다시 한번 봐야할 것 같습니다.
학습 환경
tensorflow 버전
0.12를 사용했습니다. 현재 알파 버전이 있지만, 문서에 쓰여있는 버전과 호환을 맞춰주는게 정신 건강에 좋습니다.
예를 들어서 제가 처음 이 im2txt를 접할 때에는 버전 명시가 없었습니다. 0.10 버전에서 python 3.5에 맞추어서 진행해 보려고 했었습니다. 하지만 실행이 되지 않았죠. 나중에 안 사실이지만, 0.11버전에 python 2.7 버전에서만 돌아갔습니다. 특정 함수에서 3.5에 동작하지 않는 부분이 있었습니다.
그렇기 때문에 버전을 맞추어서 사용하는게 좋습니다. 현재 버전은 0.12 버전에서 python 2.7로 작업합니다.
GPU 사용
GPU 1080 x 2개를 사용합니다. 현재 제가 관리하는 PC는 1060 1개씩 2대, 1080 2개짜리 1대 3가지입니다. 1월 13일 1080 4개가 꽂힌 제품이 입고되었습니다.
절대적으로 비례한다고는 볼 수 없지만, CPU 대비 1060이 10배 정도 빠르고, 1060보다 1080이 2배에 가깝게 빠른 느낌입니다.
결론적으로 GPU는 빠를수록 비쌀수록 좋습니다.
현재 추가적으로 GPU 1080 4개 버전도 세팅중인데 이건 기회가 되면 한번 속도 비교 해 보겠습니다.

inception_v3 모델
inception_v3를 사용한다고 하는 순간부터 GPU가 들오가는 속도 자체가 달라집니다. 이 부분은 따로 다뤄보겠습니다.
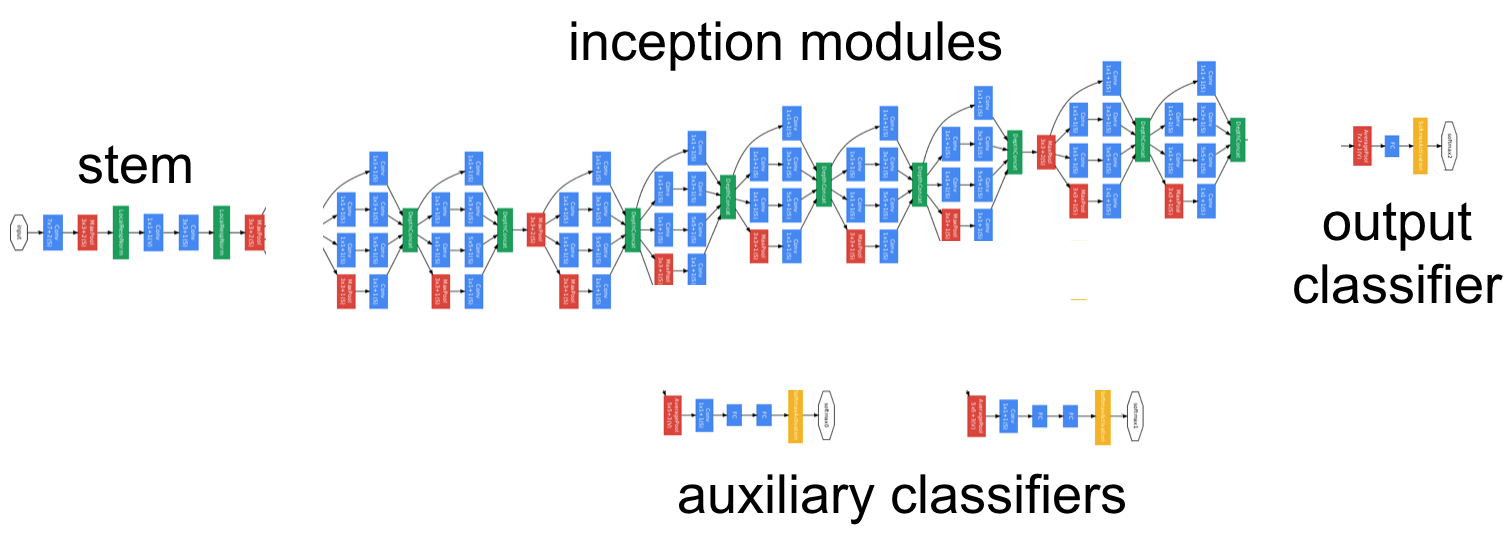
학습 데이터
MSCOCO
MS COCO 학습 데이터는 MS에서 제공합니다. 상당히 잘 정돈되어 있습니다.
학습 데이터의 확인은 여기서 하시면 됩니다.
각각의 이미지마다 다섯개의 캡셔닝이 기록되어져 있습니다.
한 번쯤은 열어보고 데이터의 모습을 보는 것도 좋을 것 같습니다.
아래와 같이 image_id 에 대해서 파일 네임이 정해집니다. 그리고, 캡션은 배열로 되어 있고 총 5개가 들어가 있습니다.
- image_id=538838
- filename=’/data/project/im2txt/data/mscoco/raw-data/train2014/COCO_train2014_000000538838.jpg’
- captions=[[‘<S>’, ‘a’, ‘fire’, ‘hydrant’, ‘with’, ‘an’, ‘out’, ‘of’, ‘service’, ‘sign’, ‘on’, ‘it’, ‘.’, ‘</S>’]]
im2txt 실습
데이터 준비
아래와 같이 입력하고 진행하면 됩니다. 아마 예제에서 보시는 모습은 bazel을 이용하여 하는 방식입니다.
아래에 예시하는 방식은 특정 폴더(mscoco/images)에 이미지가 있다는 것을 가정하고 있고, 해당 캡션이 있다는 가정하에서 사용하는 방법입니다. 더 좋은 실험을 위해서는 TRAIN과 VALID 셋을 나누는게 제일 좋겠지만, 데이터가 적은 관계로 일단 있는걸 학습시키고 학습된게 잘 나오는지 확인하기 위해서 동일한 폴더를 사용했습니다.
학습 및 평가
tensorflow im2txt를 이용한 이미지 캡셔닝 이해 및 실습 순서는 다음과 같이 진행했습니다.
# 디렉토리 만들기 (프로젝트, 실제 이미지, 변환 학습용 데이터, 학습 폴더, 평가 폴더 순)
mkdir /home/data/im2txt/mscoco
mkdir /home/data/im2txt/mscoco/images
mkdir /home/data/im2txt/mscoco/dataset
mkdir /home/data/im2txt/mscoco/train
mkdir /home/data/im2txt/mscoco/eval
mkdir /home/data/im2txt/model
# 학습을 위한 환경 변수 선업 (TRAIN 및 VALID는 분리하면 좋지만, 일단 같이 쓰기로)
export TRAIN_IMAGE_DIR=/home/data/im2txt/mscoco/images
export VALID_IMAGE_DIR=/home/data/im2txt/mscoco/images
export TRAIN_CAPTION_FILE=/home/data/im2txt/mscoco/json/Product_im2txt.json
export VALID_CAPTION_FILE=/home/data/im2txt/mscoco/json/Product_im2txt.json
export TRAIN_DATA_DIR=/home/data/im2txt/mscoco/dataset
export WORD_COUNT_FILE=/home/data/im2txt/mscoco/dataset/word_counts.txt
export MODEL_DIR=/home/data/im2txt/mscoco
export TRAIN_DIR=$MODEL_DIR/train
export EVAL_DIR=$MODEL_DIR/eval
# 학습 데이터 다운로드 및 변환
- 이미지를 ${TRAIN_IMAGE_DIR}에 다운로드
- 이미지와 캡션 데이터 json 파일을 ${TRAIN_CAPTION_FILE}에 다운로드
- 텐서플로우 학습용 데이터 셋으로 변환
cd /home/cafe24/tensorflow/models/im2txt/im2txt/data
python build_mscoco_data.py \
--train_image_dir=$TRAIN_IMAGE_DIR\
--val_image_dir=$VALID_IMAGE_DIR \
--train_captions_file=$TRAIN_CAPTION_FILE \
--val_captions_file=$VALID_CAPTION_FILE \
--output_dir=$TRAIN_DATA_DIR \
--word_counts_output_file=$WORD_COUNT_FILE
# im2txt 학습용 모델(inception_v3) 설정
- inception_v3 모델 파일을 다운로드 받고 환경 변수에 등록
cd /home/data/im2txt/model
wget "http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz"
tar -xvf "inception_v3_2016_08_28.tar.gz"
rm "inception_v3_2016_08_28.tar.gz"
export INCEPTION_CHECKPOINT=/home/data/im2txt/model/inception_v3.ckpt
# 학습
cd /home/cafe24/tensorflow/models/im2txt
bazel build -c opt im2txt/...
bazel-bin/im2txt/train \
--input_file_pattern=$TRAIN_DATA_DIR/train-?????-of-00256 \
--inception_checkpoint_file=$INCEPTION_CHECKPOINT \
--train_dir=$TRAIN_DIR \
--train_inception=false \
--number_of_steps=100000
# 평가
bazel-bin/im2txt/run_inference \
--checkpoint_path=$TRAIN_DIR \
--vocab_file=$WORD_COUNT_FILE \
--input_files=$VALID_IMAGE_DIR/23361_01_003.jpg
bazel-bin/im2txt/run_inference \
--checkpoint_path=$TRAIN_DIR \
--vocab_file=$WORD_COUNT_FILE \
--input_files=$VALID_IMAGE_DIR/23390_01_002.jpg
요약
tensorflow im2txt를 이용한 이미지 캡셔닝 이해 및 실습 방법을 알아보았습니다. 회사에서 이 프로젝트를 이용한 무언가를 진행중인데, 윗 분들이 결과 빨리 안 나온다고 닥달하시고 계십니다.
하면서 느낀 점은 절대적으로 학습에 사용할 데이터가 중요하다는 점이고요. 머신 러닝 자체가 패턴을 기반으로 학습이 되기 때문에, 사람이 봐도 안 보이는 패턴을 가진 데이터를 넣어서 해 봐야 소용 없다는걸 뼈저리게 느끼고 있습니다.
데이터 준비하는게 일의 90%가 아닐까 한데, 이미지는 어느 정도 분류 했는데, 캡션 쪽이 아직은 노답인 상태입니다. 결국 한땀한땀 마련해 나가는 방법을 고안하지 않을 수 없을 듯 합니다.


